RPC
如果要搞分布式,那必然涉及到服务之间的相互调用,即远程过程调用(Remote Procedure Call,PRC)。
RPC
想要rpc,需要哪些步骤?本能的想法,是看看本地方法调用需要哪些步骤,类比一下。因此一开始rpc所追求的目标就是:让计算机能够像调用本地方法一样去调用远程方法。
虽然现在人们已经认清现实,放弃追求“像调用本地方法一样”这个目标了:D
为此,需要先理解本地方法调用的步骤。
今天已经很难找到没有开发和使用过远程服务的程序员了,但是没有正确理解远程服务的程序员却仍比比皆是。
本地方法调用
function/method/procedure,其实都是一个意思。
一个函数调用另外一个函数,需要分析程序运行栈stack。
stack
首先看一下linux内存模型,一个linux进程(C program)的内存模型主要包含以下几部分:
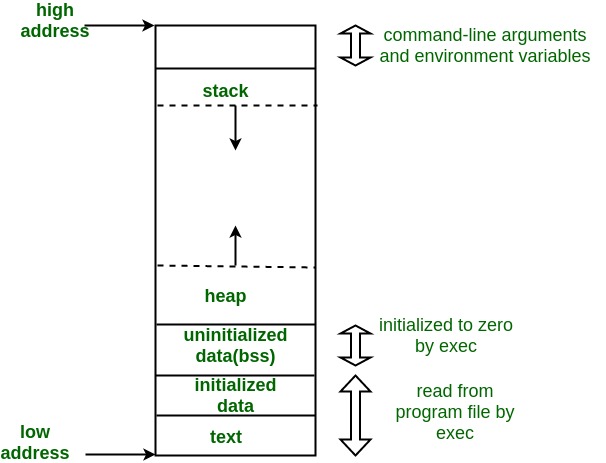
其中:
- 代码区:code segment,代表内存里程序的可执行代码(二进制)部分,包含的是可执行指令;
- stack:程序运行栈;
Java程序本质上是openJDK执行的一个c程序,它的进程内存空间同上。其中jvm的heap/stack/code segment也都分别存在于进程空间的相应部分,详见Java内存模型。
除此之外,还有几个和程序运行相关的寄存器:在cpu里,能存放一个值。这个值可能代表一个普通数值,也可能代表一个地址:
- PC:Program Counter,记录下一条要执行的程序指令(在code segment里)的地址;
- SP:Stack Pointer,指向当前程序运行栈的栈顶(在stack)的地址;
- frame pointer:当前栈帧的起始地址。frame pointer到stack pointer之间的部分就是当前函数占用的栈帧;
这是一个画的非常好的栈帧示意图(只不过一般我们画栈帧的时候上面是高地址,下面是低地址,所以栈的增长方向看起来是从上到下的,因此反过来看会更好): 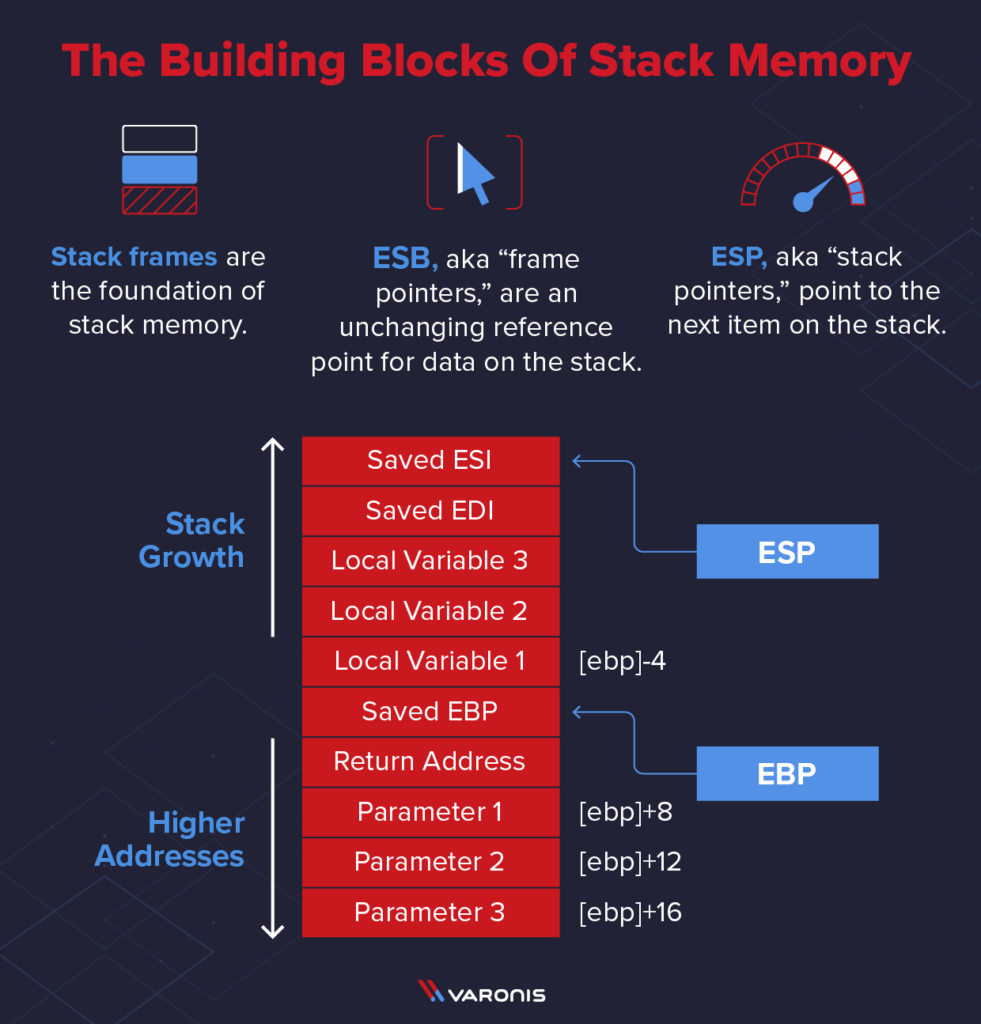
来自文章:Stack Memory: An Overview (Part 3),Neil Fox
由编译原理的课程可知,压栈顺序大概是:
- 参数逆序(压在父函数栈):以方便访问;
- return address(压在父函数栈):返回地址(不是返回值!),program counter的值,即调用子函数的那条指令的下一条要执行的指令。当程序返回的时候,要拿到这个值以继续之前的程序执行;
- previous ebp:上一个栈(父函数)的ebp;
- 子函数的局部变量(压在子函数栈):用完随栈的销毁而销毁;
所以局部变量太大或者递归层次太多会stack overflow。
为什么要压pc/ebp的值?本质道理是一样的:因为pc/ebp寄存器就一个……发生函数调用的时候,子函数也要用到这些寄存器,如果不把父函数的pc/ebp的值保存下来,被覆盖后就丢了。俗称:保存现场,以恢复上下文。至于保存到子栈帧外还是栈帧内,都行,只要会保存且只保存一次就行。所以x86的cpu规定了哪些寄存器是caller save,哪些是callee save:
- caller save:进行子函数调用前,由调用者提前保存好这些寄存器的值(保存方法通常是把寄存器的值压入堆栈中),之后在被调用者(子函数)中就可以随意覆盖这些寄存器的值了;
- callee save:在函数调用时,调用者不必保存这些寄存器的值而直接进行子函数调用,进入子函数后,子函数在覆盖这些寄存器之前,需要先保存这些寄存器的值。即这些寄存器的值是由被调用者来保存和恢复的;
有人干就行,你干了我就不用干了。参考x86-64 下函数调用及栈帧原理。
大体上是这么设计的,但是不同的cpu架构设计的并不完全一样。比如我在编译原理的课设上还在子栈帧里压了子函数的返回值。而x86架构的cpu比较壕(贵),寄存器比较多,有一个专门的rax寄存器存放子函数的返回值,栈帧上就不用保存返回值了。
rax不用像pc/ebp一样保存在栈帧上,因为:子函数先有返回值,父函数后有返回值,且父函数返回返回值的时候子函数的返回值就没用了,所以rax寄存器不会像其他寄存器一样存在相互覆盖丢数据的情况。
当发生函数调用的时候,关键步骤:
- 保存上下文:
- 压PC里的返回地址;
- 压previous ebp;
- 创建子栈帧:
- 当前esp的值写入ebp(当前的栈顶就是子函数栈的起始位置);
- 压子函数局部变量,esp继续增长;
当函数调用返回时,关键步骤:
- 恢复上下文:
- 恢复父栈帧的终点(也就是子栈帧的起点):当前ebp的值写入esp(同时相当于销毁了子栈帧);
- 恢复父栈帧起点:弹出previous ebp,写入ebp;
- 恢复程序执行的流程:弹出previous PC的值,写入pc;
RPC的三大基本问题
概括地说,本地调用子函数需要以下几个步骤:
- 传参:参数压栈;
- 确定要调用的方法:program counter指向被调用方法的地址(在此之前,pc值需要被压栈保存);
- 执行方法:为新的函数创建新的栈帧;
- 返回结果:销毁子方法的栈帧,返回值压栈;
- 恢复上下文,继续执行函数调用后的下一条指令;
这些步骤在同一个进程内都理所当然,但是如果在两个进程内,问题就麻烦很多:
- 数据表示:参数和返回值在同一个进程内,有着同一种表示方式。一旦在不同的进程内,可能会:
- 两种不同的语言,数据结构不互通;
- 不同的硬件指令集;
- 不同的操作系统big-endian/little-endian;
- 数据传输:参数和返回值怎么从一个进程发给另一个进程;
- 方法表示:怎么明确表示调用的是另一个进程里的哪个方法?如果语言不同,大家对方法的表述都不一样,比如java说调用的是
public void print(...)方法,python:public是什么意思?
这三个问题,就是RPC要解决的三大基本问题。而这些问题都来自对本地方法调用的模仿。
模仿确实是很自然的想法。
RPC:模仿不来
RPC想模仿本地方法调用,最现实的一个问题就是:怎么进行数据传输?
IPC:进程间数据交换
linux进程间通信(Inter-Process Communication,IPC)常用的方法:
- pipe:常用于传递少量字节流/字符流;
- 普通管道:拥有亲缘关系的进程(一个进程启动另一个进程)之间的通信。比如
ps | grep xxx,两个独立的进程,前者把自己的stdout接到后者的stdin上; - named pipe:任意两个进程;
- 普通管道:拥有亲缘关系的进程(一个进程启动另一个进程)之间的通信。比如
- signal:比如
kill -9,SIGTERM/SIGKILL等;- 示例:需要调用c的api,
include <signal.h>,虽然平时并没有用过,但是用过封装好的linux command;
- 示例:需要调用c的api,
- semaphore:翻译成信号量太容易和signal信号弄混了,不如不翻译了。进程间同步的手段,和线程间同步一样,就是拿一个特殊变量充当锁,在上面进行wait/notify。只不过这个特殊变量是由操作系统提供的;
- 示例:需要调用c的api,
include <semaphore.h>,所以平时并没有用过;
- 示例:需要调用c的api,
- message queue:用于进程间大量数据传输。实际写法跟调用kafka/socket的api发送/接收数据差不多,只不过这个queue在linux里;
- 示例:需要调用c的api,
include <sys/msg.h>,所以平时并没有用过;
- 示例:需要调用c的api,
- shared memory:效率最高的ipc方式。原本进程的内存地址空间相互隔离,通过shared memory主动创建、维护某一块内存。当然一般需要使用信号量控制同步。和多线程读同一块区域类似。
- 示例:需要调用c的api,
include <sys/shm.h>,所以平时并没有用过;
- 示例:需要调用c的api,
- UNIX domain socket:又叫IPC socket,仅指本机的socket通信。跨机器走网络的socket(
AF_INET)就叫socket,不叫IPC socket(AF_LOCAL)。IPC socket要比socket快很多,因为不经过网络协议栈,不封包拆包、也不用计算校验和、不发送ack;- 示例:这个就不举例了,用得太多了;
还有一些很好的示意图。
ipcs命令可以查看linux系统的semaphore/message queue/shared memory使用情况:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
Ξ ~ → ipcs -a
------ Message Queues --------
key msqid owner perms used-bytes messages
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
------ Semaphore Arrays --------
key semid owner perms nsems
Ξ ~ → ipcs -l
------ Messages Limits --------
max queues system wide = 32000
max size of message (bytes) = 8192
default max size of queue (bytes) = 16384
------ Shared Memory Limits --------
max number of segments = 4096
max seg size (kbytes) = 18014398509465599
max total shared memory (kbytes) = 18014398509481980
min seg size (bytes) = 1
------ Semaphore Limits --------
max number of arrays = 32000
max semaphores per array = 32000
max semaphores system wide = 1024000000
max ops per semop call = 500
semaphore max value = 32767
通信成本
rpc算不算一种ipc?从概念上看,绝对算。但是rpc的通信成本不像上述ipc方法一样可以被上层使用人员忽略。一旦上层程序员不考虑rpc的通信成本随意调用,对程序来说将会是灾难,因为网络是不可靠的、有延迟的、带宽有限、不安全……
所以:rpc是一种高层次/语言层次的特征,ipc是一种低层次/系统层次的特征,二者不是一个层面的东西。两个不同领域的东西是不存在包含关系的,所以说rpc不是一种ipc!
这一观点和既然有 HTTP 请求,为什么还要用 RPC 调用?是类似的,其认为restful不是rpc的一种,除非以非常宽泛的概念理解rpc。
同样,如果够宽泛,甚至也可以认为restful是一种ipc。这种在概念上的宽泛的理解意义不大,还是把他们看成并列的方案,更能看出他们的区别。
RPC现状
rpc虽然模仿ipc未遂(“像调用本地方法一样”),性能上做不到,但逻辑上还是模仿得来的——只要能搞定这三个问题:
- 数据表示(序列化,eg:protobuf);
- 数据传输(eg:tcp、http2);
- 方法表示(IDL,eg:protobuf);
抓住rpc和本地方法调用的类比关系,对理解rpc的本质很有帮助。
然而想用一个统一的方案搞定这三个问题非常难,没有谁能做到简单、普适、高性能:
- 想要语言无关,就会麻烦:比如用Interface Description Language(IDL,接口描述语言)以和语言无关的方式描述接口;
- 想要简单,功能就不会齐全:比如用http传输数据,可以少考虑一些底层细节,但肯定不如tcp快;
- 想要提升效率二进制传输,就要对每一种语言单独支持;
- 等等;
所以到现在出现了各种类型的rpc框架,分别瞄准不同的目标:
- 性能:序列化效率、信息密度(传输协议层次越高,信息密度越低)
- gRPC:使用protocol buffer、http2;
- thrift:tcp;
- 面向对象(分布式对象,distribution object):不满足rpc只将面向过程编码方式带到分布式领域,要在分布式系统中进行跨进程的面向对象编程
- RMI
- 简单:
- JSON-RPC:功能最弱、速度最慢的rpc之一。但真的非常简单!而且所有主流语言都支持(其实是主流语言都支持http,hhh);
还有一个趋势:以插件的方式集成rpc的三个基本问题的解决方案,让用户自己权衡。框架本身则多做一些更高层次的功能,比如分布式的负载均衡、服务注册等。比如dubbo。
如果换个思路
分布式一定要使用rpc吗?
仔细想想,rpc的三大问题来自对本地方法调用的模拟。如果换个思路,不模拟“方法调用”,那么看待数据表示、数据传递、方法表示这三个问题时就会有全新的视角——Representational State Transfer,REST!
JSON-RPC
来看看json-rpc究竟有多简单——
简单到specification 2.0甚至都没有几行字。不过依然一本正经地像其他RFC一样用规范化的语言进行specification的表述。
难兄难弟:XML-RPC
用json代表数据,所以一共六种数据类型:JSON can represent
- four primitive types (
Strings,Numbers,Booleans, andNull) - and two structured types (
ObjectsandArrays)
比如批量request:
1
2
3
4
5
6
7
8
[
{"jsonrpc": "2.0", "method": "sum", "params": [1,2,4], "id": "1"},
{"jsonrpc": "2.0", "method": "notify_hello", "params": [7]},
{"jsonrpc": "2.0", "method": "subtract", "params": [42,23], "id": "2"},
{"foo": "boo"},
{"jsonrpc": "2.0", "method": "foo.get", "params": {"name": "myself"}, "id": "5"},
{"jsonrpc": "2.0", "method": "get_data", "id": "9"}
]
批量response:
1
2
3
4
5
6
7
[
{"jsonrpc": "2.0", "result": 7, "id": "1"},
{"jsonrpc": "2.0", "result": 19, "id": "2"},
{"jsonrpc": "2.0", "error": {"code": -32600, "message": "Invalid Request"}, "id": null},
{"jsonrpc": "2.0", "error": {"code": -32601, "message": "Method not found"}, "id": "5"},
{"jsonrpc": "2.0", "result": ["hello", 5], "id": "9"}
]
三大问题的解决方案:
- 数据表示:文本。直接在json里写上具体的参数值(params)、返回值(result);
- 数据传输:比如http;
- 方法表示:文本。直接在json里写上方法名(method,甚至都不用写参数类型,看来是不支持重名方法的。当然方法也是全局的,没有类的概念);
json-rpc只规定了使用json进行数据表示,并没有限定具体传输协议:
It is transport agnostic in that the concepts can be used within the same process, over sockets, over http, or in many various message passing environments.
所以如果要支持多种协议,实现的代码也不少,比如:jsonrpc4j。
感想
什么感觉?就好像我是地球人,但今天才知道这竟然是一个三体的世界!
rpc的本质、换个思路看rpc就能引出另一种方案rest。我灌顶了。