Elasticsearch:pipeline
最近对Elasticsearch的pipeline研究的比较多一些,主要是做一些数据类任务:如果只是进行离线处理的话,需要先查es,再处理数据,最后写回es。除了有查询的开销之外,最大的问题就是无法做到在数据一开始写入es时进行实时处理。而ingest pipeline则解决了这个问题,在数据ingest的时候,就对其进行处理。不仅能实时处理数据,还把处理数据的开销分摊到了每一次数据写入上。
这些处理的步骤,组成了一个pipeline。
ingest pipeline
- https://www.elastic.co/guide/en/elasticsearch/reference/current/ingest.html
ingest pipeline理解起来比较直白,关键是在整个pipeline上,能做哪些操作。组成pipeline的操作的是各类processor,所以其实就是学习一下各种processor的用法。
pipeline api
- create: https://www.elastic.co/guide/en/elasticsearch/reference/current/put-pipeline-api.html
- delete: https://www.elastic.co/guide/en/elasticsearch/reference/current/delete-pipeline-api.html
pipeline可以重复创建,会直接覆盖上次的同名pipeline。设置pipeline主要就是设置processor,各个processor顺次执行。
_simulate
学习pipeline之前,先来了解一个非常重要的api:_simulate,用来测试pipeline是否符合预期。
比如搞一个pipeline:删掉数据里的年龄,如果身高大于180就增加一个tall tag
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
PUT _ingest/pipeline/student_process
{
"processors": [
{
"remove": {
"field": "age",
"ignore_missing": true
}
},
{
"set": {
"field": "tag",
"value": "tall",
"if": "ctx['height'] > 180"
}
}
]
}
然后使用simulate api模拟它在不同数据上的表现,可以添加verbose参数,详细展示每一步操作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
POST /_ingest/pipeline/_simulate?verbose
{
"pipeline": {
"processors": [
{
"pipeline": {
"name": "student_process"
}
}
]
},
"docs": [
{
"_source": {
"name": "pikachu",
"age": 12,
"height": 171
}
},
{
"_source": {
"name": "raichu",
"height": 192
}
}
]
}
结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
{
"docs" : [
{
"processor_results" : [
{
"processor_type" : "pipeline",
"status" : "success"
},
{
"processor_type" : "remove",
"status" : "success",
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"name" : "pikachu",
"height" : 171
},
"_ingest" : {
"pipeline" : "student_process",
"timestamp" : "2022-08-26T15:43:39.3629978Z"
}
}
},
{
"processor_type" : "set",
"status" : "skipped",
"if" : {
"condition" : "ctx['height'] > 180",
"result" : false
}
}
]
},
{
"processor_results" : [
{
"processor_type" : "pipeline",
"status" : "success"
},
{
"processor_type" : "remove",
"status" : "success",
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"name" : "raichu",
"height" : 192
},
"_ingest" : {
"pipeline" : "student_process",
"timestamp" : "2022-08-26T15:43:39.3630112Z"
}
}
},
{
"processor_type" : "set",
"status" : "success",
"if" : {
"condition" : "ctx['height'] > 180",
"result" : true
},
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"name" : "raichu",
"tag" : "tall",
"height" : 192
},
"_ingest" : {
"pipeline" : "student_process",
"timestamp" : "2022-08-26T15:43:39.3630112Z"
}
}
}
]
}
]
}
对于pikachu,remove执行成功,set则跳过了,因为不满足if前置条件;对于raichu,remove执行成功,set也执行成功。其中,每一个processor执行过后的数据状态也一一进行了展示。
再看一个remove object field的例子——
要删除hello下的similarity,所以hello应该是一个object:
1
2
3
4
5
6
7
8
9
10
11
12
PUT _ingest/pipeline/remove_similarity
{
"description": "remove hello.similarity",
"processors": [
{
"remove": {
"field": "hello.similarity",
"ignore_missing": true
}
}
]
}
我们预期pika和pikachu都会被删掉:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
POST /_ingest/pipeline/_simulate?verbose
{
"pipeline": {
"processors": [
{
"pipeline": {
"name": "remove_similarity"
}
}
]
},
"docs": [
{
"_source": {
"hello.similarity": "pika",
"hello": {
"similarity": "pikachu"
},
"age": 12,
"height": 171
}
}
]
}
结果只有pikachu被删掉了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
{
"docs": [
{
"processor_results": [
{
"processor_type": "pipeline",
"status": "success"
},
{
"processor_type": "remove",
"status": "success",
"doc": {
"_index": "_index",
"_version": "-3",
"_id": "_id",
"_source": {
"hello.similarity": "pika",
"hello": {},
"age": 12,
"height": 171
},
"_ingest": {
"pipeline": "remove_similarity",
"timestamp": "2024-05-21T03:45:36.742463115Z"
}
}
}
]
}
]
}
可能对于simulate api来说,没有把hello.similarity这个field转成object,直接把给出的doc当做最终的doc来处理了。
processor
processor才是pipeline的灵魂!
根据我最近的观察,pipeline用的最多的pipeline有:
- remove
- set:添加简单数据
- enrich:根据其他的数据库,做映射匹配,并添加匹配到的数据
- script:(最后的processor,杀手锏)当要做的功能比较复杂,其他processor都太简单时,直接使用script写代码处理数据。当然,如果其他processor直接就能做到,直接使用其他processor会更简单直白
- foreach:处理数组数据的processor
- pipeline:一个processor,用于引用其他pipeline。有了这个,pipeline之间就可以像函数一样相互“调用”了
其他还有很多,用到了再研究。所以processor非常丰富,功能强大。
remove
- https://www.elastic.co/guide/en/elasticsearch/reference/current/remove-processor.html
remove processor非常简单。主要注意它有两个设置:
- if:设置前置条件;
- ignore_missing:默认为false,如果数据里没有这个field,会报错;
另外它的field看起来是单数,实际可以设置单个field,也可以设置一个数组,一次性删除多个field。
script
- https://www.elastic.co/guide/en/elasticsearch/reference/current/script-processor.html
只要有processor可用,就不用script。实在没有合适的processor了,script就是最后的希望。
比如,要从数据的description字段里提取所有的url。虽然有grok processor,但它只能提取一个url,不能多次提取。这时候就要使用script processor写代码了。
多次匹配description里的url,并以数组的形式放到新的urls字段里:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
PUT _ingest/pipeline/urls_extract
{
"processors": [
{
"script": {
"description": "Extract urls from 'description' into 'urls' if url does exist",
"lang": "painless",
"source": """
def m = /(http|https):\/\/([\w_-]+(?:\.[\w_-]+)+)([\w.,@?^=%&:\/~+#-{}]*[\w@?^=%&\/~+#-{}])/i.matcher(ctx['description']);
Set urls = new HashSet();
while (m.find()) {
urls.add(m.group());
}
if (!urls.isEmpty()) {
ctx['urls'] = new ArrayList(urls);
}
""",
"if": "ctx['description'] != null && ctx['urlStatus'] != 'writing'"
}
}
]
}
注意null值处理,如果description为null代码会报错。对null的判断可以放在代码里,也可以放在if属性里。
enrich
- https://www.elastic.co/guide/en/elasticsearch/reference/current/enrich-processor.html
enrich也是在增添数据,但是增添的数据来自另一个索引:
- https://www.elastic.co/guide/en/elasticsearch/reference/current/ingest-enriching-data.html
enrich首先要设置一个enrich policy,指定怎么根据另一个索引匹配数据。
假设提取出urls之后,需要获取每个url对应的“推广信息”,而我们恰好已经有了一个索引url_info,放的全是url和它对应的推广信息。那就可以直接使用url_info这个数据库,把推广信息enrich过来。
首先可以设置一个policy:从url_info里enrich数据(所以里放的是url和它对应的rawUrl),匹配的字段(key)是url,匹配后添加的字段(values)是rawUrl/platform/brandId/type等:
1
2
3
4
5
6
7
8
PUT _enrich/policy/url_lookup_policy
{
"match": {
"indices": "url_info",
"match_field": "url",
"enrich_fields": ["rawUrl", "platform", "brandId", "type"]
}
}
即使不写入enrich_fields,match_field也会作为被enrich的field之一出现在最终enrich的数据里。
然后根据policy生成一个enrich index:
1
PUT _enrich/policy/url_lookup_policy/_execute
- enrich policy: https://www.elastic.co/guide/en/elasticsearch/reference/current/put-enrich-policy-api.html
- exec policy: https://www.elastic.co/guide/en/elasticsearch/reference/current/execute-enrich-policy-api.html
不幸的是policy不支持像pipeline一样直接覆盖更新。必须先删掉再添加,而删掉的时候必须没有pipeline在引用它,否则还删不掉。所以就很麻烦。
enrich index其实是一个.enrich-<index>-<timestamp>命名的索引,可以理解为:
- 原索引是“源代码”;
- enrich index是“编译后”的产物;
新加入原索引的数据不会被匹配到,除非execute后生成新的enrich index。就好像源代码新增了一些功能并没有什么用,编译之后才能生效。
如果数据量较大,生成enrich index类似reindex的过程,创建好索引之后数据量慢慢增加。enrich index彻底生成之后,旧的enrich index会被自动删掉。
终于可以根据policy设置enrich processor了——
数据中要匹配的字段是urls(多个url),使用的policy是刚刚的url_lookup_policy(所以和urls匹配的字段是url_info里的url字段,匹配后添加的是url/rawUrl/platform/brandId/type字段)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
PUT _ingest/pipeline/url_lookup
{
"processors": [
{
"enrich": {
"description": "Lookup raw_url info for every url(64 urls at most)",
"policy_name": "url_lookup_policy",
"field": "urls",
"target_field": "rawUrls",
"max_matches": 64,
"override": true,
"ignore_missing": true,
"if": "ctx['description'] != null && ctx['urlStatus'] != 'writing'"
}
}
]
}
如果max_matches > 1,enrich的数据是一个数组(否则是一个json object)。因为:
- 一个url可能匹配到多个url_info里的url;
- 更何况urls本身就是多值的,会匹配到url_info里的多个url;
target_field是数组的名字。
foreach
- https://www.elastic.co/guide/en/elasticsearch/reference/current/foreach-processor.html
专门为array设计的:对array的每一个值执行一次processor。所以它的功能其实都体现在这个“内嵌的”processor里。
比如上面的每个url都找到了rawUrl,并存放到了数组rawUrls里。假设每个rawUrl都有一个对应的商品信息,那么就可以对每个rawUrl再来一次enrich,给他们都添加上branding信息(省略branding_lookup_policy,和url_lookup_policy类似):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
PUT _ingest/pipeline/branding_lookup
{
"processors": [
{
"set": {
"field": "urlStatus",
"value": "none",
"if": "ctx['urls'] == null"
}
},
{
"set": {
"description": "Set 'urlStatus'='matching' if any url can't find raw_url. 2: ANDROID & IOS",
"field": "urlStatus",
"value": "matching",
"if": "ctx['urls'] != null && (ctx['rawUrls'] == null || (ctx['rawUrls'] != null && 2 * ctx['urls'].length > ctx['rawUrls'].length))"
}
},
{
"set": {
"description": "Set 'urlStatus'='matched' if all urls can find corresponding raw_url. 2: ANDROID & IOS",
"field": "urlStatus",
"value": "matched",
"if": "ctx['urls'] != null && ctx['rawUrls'] != null && (2 * ctx['urls'].length <= ctx['rawUrls'].length || ctx['rawUrls'].length == 64)"
}
},
{
"foreach": {
"description": "Lookup branding info for every raw_url",
"field": "rawUrls",
"processor": {
"enrich": {
"description": "Enrich branding info",
"policy_name": "branding_lookup_policy",
"field": "_ingest._value.brandId",
"target_field": "_ingest._value.brandingAnalyses",
"ignore_missing": true,
"override": true
}
},
"ignore_missing": true
}
},
{
"set": {
"description": "Set 'urlStatus'='branding' after branding lookup for 'urlStatus'='matched'",
"field": "urlStatus",
"value": "branding",
"if": "ctx['urlStatus'] == 'matched'"
}
}
]
}
所以写foreach主要就是写内嵌的processor的。这里用的是一个enrich processor。
如果想访问当前正在遍历到的array里的值,可以使用_ingest.value引用它:
- https://www.elastic.co/guide/en/elasticsearch/reference/current/foreach-processor.html#foreach-keys-values
比如上述enrich就是使用当前值(rawUrl)的brandId("field": "_ingest._value.brandId")做匹配,匹配后的结果写到当前值(rawUrl)下,命名为brandingAnalyses字段("target_field": "_ingest._value.brandingAnalyses")。
pipeline
- https://www.elastic.co/guide/en/elasticsearch/reference/current/pipeline-processor.html
pipeline之间相互调用。
比如把上面所有的pipeline组合起来,就是一条大的pipeline:
- 从description里提取urls;
- urls里的每一个url都尝试enrich其rawUrl,最终都放到rawUrls数组里;
- 遍历rawUrls数组,给每个rawUrlenrich品牌信息,放到每个rawUrl下的brandingAnalyses里:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
PUT _ingest/pipeline/branding { "processors": [ { "pipeline": { "name": "urls_extract" } }, { "pipeline": { "name": "url_lookup" } }, { "pipeline": { "name": "branding_lookup" } } ] }
完美。
整个数据处理的流程如图: 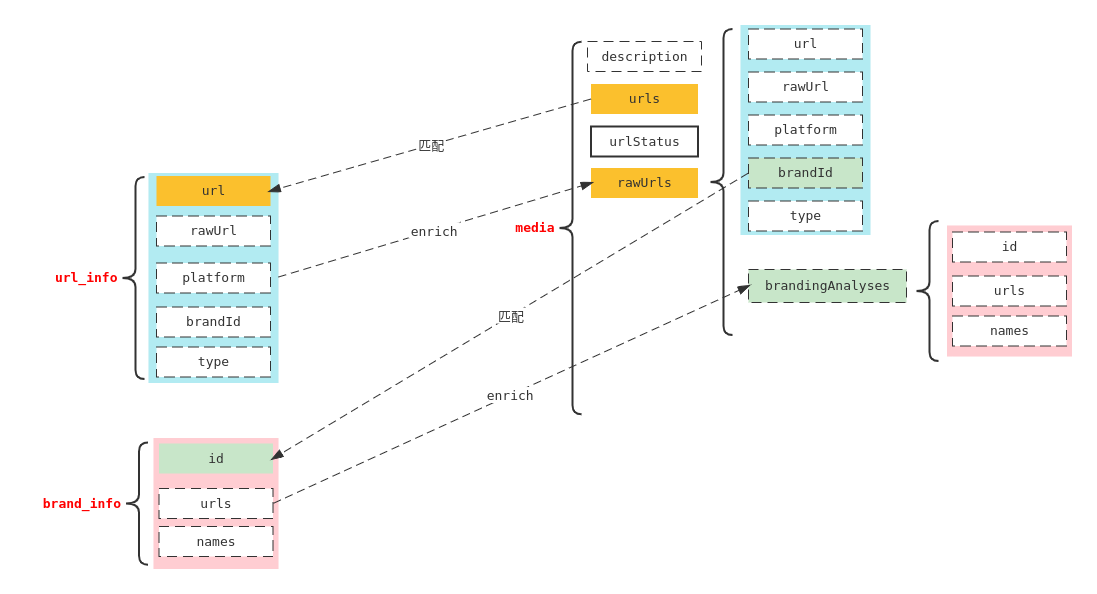
使用pipeline
使用pipeline还挺麻烦:
_update接口不支持pipeline;_update_by_query接口支持pipeline参数,但是好像也受限;_bulk接口也支持pipeline参数,但是具体到batch里的每一条,又有的支持有的不支持。实测证明,bulk里的update请求不支持,index据说可以(这就很坑了,接口明明有pipeline这个参数,却只能部分支持……文档还没说……):- https://github.com/elastic/elasticsearch/issues/30627#issuecomment-389500305
最终我发现给index设置个default_pipeline可以完美解决这个问题:
- https://www.elastic.co/guide/en/elasticsearch/reference/current/ingest.html#set-default-pipeline
不管是PUT还是update,最终都会触发default pipeline。
update比较特殊。比如文档有a和b两个field,且都有值,update请求里只含a,那么pipeline的if条件
ctx['a'] != null && ctx['b'] != null为true还是false?true!其他field也算出现在这个请求里了,估计因为update本身就是“先取出其他的field,再和新的a值一起组成个新的文档,写入索引”。而这一点貌似是simulate api没法模拟的。毕竟simulate里的doc如果只出现a,那就只有a,没有b。此时
ctx['a'] != null && ctx['b'] != null为false。
性能分析
还能统计pipeline的使用频率和时间消耗,强啊:
- https://www.elastic.co/guide/en/elasticsearch/reference/current/ingest.html#get-pipeline-usage-stats