Java Collection Framework
Java Collection Framework, JCF,Java集合框架。JDK提供了很多丰富的工具集合,其他比如guava也补充了jdk里没有的更为丰富的工具集合。了解这些工具集合,就可以在不同的场景选用不同的工具,提升效率而且编程实现的会很漂亮。
- 接口
- Collection
- List
- Set
- Queue
- Deque - interface
- Map
- LinkedHashMap(& LinkedHashSet)
- Collections - 关于Collection的工具类
- 其他 - Guava
接口
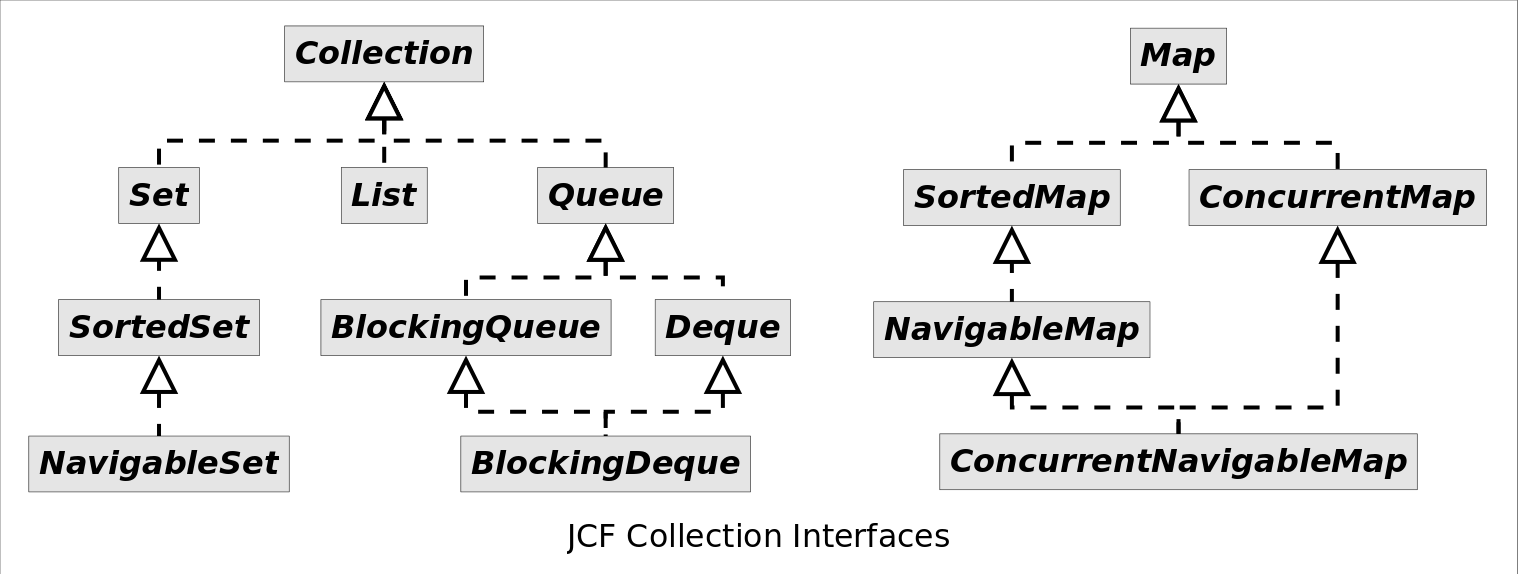 图片来源:https://github.com/CarpenterLee/JCFInternals/blob/master/PNGFigures/JCF_Collection_Interfaces.png
图片来源:https://github.com/CarpenterLee/JCFInternals/blob/master/PNGFigures/JCF_Collection_Interfaces.png
Collection:
- List;
- Set;
- Queue;
- Deque(Double Ended Queue);
Map不属于集合,所以这个接口不是Collection接口的子类。
Note:
Collection中有add(E),List继承它,但接口中也声明了这种方法,那是因为虽然都是add,但它对该方法进行了更细粒度的定义。
Collection
增删查:
add;remove;contains;
遍历:
- iterator();
Collection
extends Iterable
其他:
isEmpty;clear;iterator;size;toArray;clear;
对集合的操作:
addAll;removeAll;containsAll;retainAll,求交;removeIf(Predicate<? super E> filter);
List
新增的,基本都是和位置index有关:
add(E);add(int index, E),增加E到index位置;E set(int index, E element),设置index位置的元素;get(int index),获取index位置的元素;int indexOf(Object o),获取元素第一次出现的位置;int lastIndexOf(Object o),获取最后一次元素出现的位置;E remove(int index),删除index位置的元素;default void sort(Comparator<? super E> c),排序;List<E> subList(int fromIndex, int toIndex),获取子序列;
ArrayList
底层使用数组。
LinkedList
LinkedList<E> implements List<E>, Deque<E> 底层使用双向链表来实现。
最骚的是,它还同时实现了
Deque接口(Deque继承了Queue接口),所以它是一个顺序容器队列,同时可以作为队列,还可以作为栈。
Deque在JDK1.6引入,代替Stack,Stack在JDK1.0引入,是个类而非接口,继承Vector,被弃用了。 关于栈或队列,现在的首选是ArrayDeque,它有着比LinkedList(当作栈或队列使用时)有着更好的性能。
Set
和Collection比,没有新增的方法。很多set的实现都“偷懒”,直接使用map的keySet作为自己的内容。比如HashMap -> HashSet,TreeMap -> TreeSet等。
大家的key对应的value基本都是随便找的同一个无意义的object。
Queue
在队尾新增元素,并从队首取出。
add(E)->offer(E),在队尾增加;remove()->poll(),在队首删除;element()->peek(),获取队首元素内容;
前者在没空间add、删除空队列、获取空队列的首元素时,会抛异常,后者则返回null或false。
PriorityQueue
Queue的实现类。
队列先进先出,是以元素添加顺序作为判断“先”与“后”的条件。优先级队列由用户自定义的Comparator作为判断先后的条件,而不是考虑元素添加顺序。如果没有自定义Comparator,使用元素的自然序。权重最小的为“先”,排在队列最前面。
实现
PriorityQueue实际上是一个堆,或者说完全二叉树(complete binary tree)。由于权重最小的在最顶端,所以就是一个小顶堆:非叶子节点的权重不大于其左右子节点。
完全二叉树:最后一层的节点都集中在最左边,其它层节点都满。
完全二叉树可以使用数组来实现:The two children of queue[n] are queue[2*n+1] and queue[2*(n+1)], parentNumbuer = (childNodeNumber - 1) / 2。JDK里的PriorityQueue的底层就是一个Object数组。
siftUp / siftDown
- siftUp:以某个节点为指定节点,递归和其父节点比较,如果权重小于其父节点,交换位置,直到顶端,或者直到父节点权重小于该节点;
- siftDown:以某个节点为root,比较其与子节点的权重,如果权重大于两个子节点的最小值,则和那个节点交换,直到沉底,或者权重不小于其子节点。
add()/offer() - O(logN)
增加元素时(add / offer),增加到堆的末端,所以要对末端节点来一次siftUp。
remove()/poll() - O(logN)
按照Queue的定义,删除的元素恒为权重最小的值,即堆顶。所以将最后一个元素放到堆顶,来一次siftDown。
element()/peek() - O(1)
返回数组中第0个元素(堆顶)即可。不涉及到堆结构变动。
remove(Object) - O(logN)
删除某一元素时(remove(E),Collection接口的方法),如果删的不是最后一个元素,就把最后一个元素放到该位置,然后对该位置来一次siftDown。
BlockingQueue - interface
java.util.concurrent,用于并发场合,阻塞队列,非常适合做生产者消费者模式中的共享队列。
新增阻塞方法:
put(E);take();
ArrayBlockingQueue
BlockingQueue的基础实现,底层使用的是数组。
DelayQueue
BlockingQueue的实现类。里面放置的是实现了Delayed接口的元素。
Delayed接口提供了
getDelay()方法,返回尚需延迟的时间。Delayed还继承了Comparable接口,所以还要实现compareTo()方法,用来决定getDelay返回的延迟时间的排序顺序,究竟是delay大的优先还是小的优先。
- 只能取出expired元素(delay <= 0),否则size不为零,但是poll()返回null;
- head为按照delay排序后最小或最大的元素;
由于每次取最大(或最小)delay,所以DelayQueue底层用了PriorityQueue堆来排序。(元素的自然序,即Delayed接口的compartTo方法) 又因为实现的BlockingQueue的put/take方法阻塞,所以使用了Lock + Condition的await/signal机制实现阻塞。
Deque - interface
Deque<E>extendsQueue<E>
Deque接口是栈和队的结合体:可以在队首或队尾放置或者取出元素。(Queue只能队尾放,队首取;Stack只能队尾放,队尾取。)
Deque的含义是“double ended queue”,即双端队列,两头都可以操作。它既可以当作栈使用,也可以当作队列使用。
Deque vs Queue
下表列出了Deque与Queue相对应的接口方法:
| Queue Method | Equivalent Deque Method | 说明 |
|---|---|---|
add(e) | addLast(e) | 向队尾插入元素,失败则抛出异常 |
offer(e) | offerLast(e) | 向队尾插入元素,失败则返回false |
remove() | removeFirst() | 获取并删除队首元素,失败则抛出异常 |
poll() | pollFirst() | 获取并删除队首元素,失败则返回null |
element() | getFirst() | 获取但不删除队首元素,失败则抛出异常 |
peek() | peekFirst() | 获取但不删除队首元素,失败则返回null |
Deque vs Stack
下表列出了Deque与Stack对应的接口方法:
| Stack Method | Equivalent Deque Method | 说明 |
|---|---|---|
push(e) | addFirst(e) | 向栈顶插入元素,失败则抛出异常 |
| 无 | offerFirst(e) | 向栈顶插入元素,失败则返回false |
pop() | removeFirst() | 获取并删除栈顶元素,失败则抛出异常 |
| 无 | pollFirst() | 获取并删除栈顶元素,失败则返回null |
peek() | peekFirst() | 获取但不删除栈顶元素,失败则抛出异常 |
| 无 | peekFirst() | 获取但不删除栈顶元素,失败则返回null |
上面两个表共定义了Deque的12个接口。添加,删除,取值都有两套接口,共2*3=6个,它们功能相同,区别是对失败情况的处理不同。每套接口都有对首尾的操作(xxxFirst()、xxxLast()),所以有6*2=12个接口。
其实Deque有12+6=18个接口方法,因为它本身继承了Queue接口,所以还要实现Queue的方法。 实际上Deque在实现Queue的add的时候,直接就调用了Deque的addLast方法。
ArrayDeque
底层使用数组来实现双端队列。
官方推荐的Stack和Queue的实现,性能高于LinkedList。
因为可能会从头插或者从头删,所以这个数组当做循环数组(circular array)来用。否则每次从头插一个元素都要把后面的每个元素都后移一位,效率太差。
循环数组:并不是说数组的形状是循环的,而是使用了head和tail两个指针,可以指向数组的任何一个位置,任意一个点都可以看做起点或终点,逻辑上相当于一个循环数组。
LinkedList
如前所述,Deque(或者说Queue)的另外一个基础实现就是LinkedList。
全能型选手,可以作为List、Queue、Stack、Deque来使用。
Map
key -> value.
HashMap(& HashSet)
base
- capacity: 16;
- loadFactor: 0.75
这样就能算出threshold(loadFactor就没啥用了)。一旦当前元素数量(size)大于threshold,就开始resize。
- threshold: 16 * 0.75 = 12;
- size
插入元素的时候,大致就是:size < threshold < capacity
形状
一个长度为capacity的Node数组,数组的每个元素是一个链表(存放hash冲突的元素)。
每个Node里面有:
- key;
- value;
- hash;
- next指针;
key value肯定是有的。hash主要是存储该节点的hash值,日后resize的时候还要用呢。
capacity -> 处理为2^n
TODO: tableSizeFor()
put
放在第hash & (capacity-1)个桶。
capacity是2^n,以二进制的视角来看这个式子,capacity-1是全1,再加上与操作,其实就是:hash值的低capacity位(从capacity-1到0)决定了元素所在的桶。
TreeNode
TODO
resize
当size > threshold时,开始resize。
- capacity倍增;
- 新建一个长度为2 * capacity的Node数组;
- 遍历旧数组,挪原来数组位置上对应的链表;
- 把旧数组元素置null;
移动之后,效果和“将所有元素rehash”一样,但是jdk源码并不是这么做的,而是有个更高效的操作:
- 遍历旧数组;
- 对每一个元素(单元素或链表)进行判断;
- 如果是单元素,直接rehash一下,放到新的数组里(问题一);
- 如果是链表(问题二):
- 按照每一个元素的
hash & oldCapacity是否为0,拆分到hi和lo两个链表里; - 假设当前位置在数组里的index为j:lo放到新数组的j位置,hi放到新数组的j+oldCapacity位置;
- 按照每一个元素的
问题一:旧数组会不会有两个单元素,但是rehash后在新数组的同一个位置?
不会。resize其实就是将一个bin拆分为两个bin。在旧bin的元素只会出现在新的两个bin中的其中一个。其他位置的旧bin不可能出现在这两个新bin里。
问题二:为啥判断条件是(hash & oldCapacity) == 0?
联想一下上面的,判断在哪个桶用到的是
hash & (capacity-1),在新桶的位置应该用hash & (newCapacity-1)来判断。但是我们已经知道,旧桶只会分成两个新桶,所以只需要知道在哪个新桶里就行了。oldCapacity-1位就是决定在新桶的高位桶还是低位桶的:
- 如果该位为0,那就跟旧桶的index一样,即新桶的low桶;
- 如果该位为1,那就在新桶的high桶,即旧桶的index+oldCapacity位置;
- https://segmentfault.com/a/1190000015812438
- https://stackoverflow.com/a/58213532/7676237
但是我有个小问题:这样拆分为两个链表,也得遍历。跟直接遍历并rehash每个元素在性能上有啥区别呢?
keySet()/entrySet()/values()
并不是把map的key收集成一个set返回,而是呈现了一个set的视图:
- 继承自AbstractSet:需要实现iterator方法,add方法会抛异常;
- map的keySet只实现了iterator,没实现add,所以不能往里add数据;
所以这并不是一个正常的有增删改查功能的,有实体的set,而只是一个map所呈现出来的set视图。
keySet/entrySet/values 三个方法其实共用了map的内部的一个iterator(HashIterator),提供了遍历map的Node节点的nextNode()方法。entrySet利用它取entry(Node是Entry的实现类),keySet利用它取key,values利用它取value。
只不过values()返回的不是Set而是Collection。所以values用的是一个继承了AbstractCollection的Values内部集合。
遍历的顺序问题
遍历key或value或entry(他们都是同一种遍历方式:HashIterator)的顺序都是相同的:
- 按照index递增遍历数组;
- 遍历每个位置的链表;
返回的key set、value Collection和value set都用的这个iterator,所以大家的遍历都是这个顺序。
Map.Entry
Entry只是提供key和value的一个抽象接口定义。在HashMap里,它的实现就是Node。
LinkedHashMap(& LinkedHashSet)
map的各个节点都使用双向链表,从而保留了添加的顺序。
base
它的Entry是HashMap.Node的子类,除了key、value、hash、next指针,又新增了两个指针:
- before;
- after;
为了构建链表,LinkedHashMap里(不是Entry里)还有两个指针:
- head;
- tail;
LinkedHashMap的创建Node(Entry)的方法newNode()不太一样,多了一步linkNodeLast(),主要用于:
- 将新插入节点的before指向旧tail;
- 将旧tail的after节点指向新节点;
遍历:LinkedHashIterator
LinkedHashMap的遍历就相当简单了。不需要按照数组+链表去遍历,只需要抓住head节点,依次遍历节点的after即可。
所以是:按插入序遍历!
LinkedHashMap经典用法
LinkedHashMap除了可以保证迭代顺序外,还有一个非常有用的用法:可以轻松实现一个采用了FIFO替换策略的缓存。具体说来,LinkedHashMap有一个子类方法protected boolean removeEldestEntry(Map.Entry<K,V> eldest),该方法的作用是告诉Map是否要删除“最老”的Entry,所谓最老就是当前Map中最早插入的Entry,如果该方法返回true,最老的那个元素就会被删除。在每次插入新元素的之后LinkedHashMap会自动询问removeEldestEntry()是否要删除最老的元素。这样只需要在子类中重载该方法,当元素个数超过一定数量时让removeEldestEntry()返回true,就能够实现一个固定大小的FIFO策略的缓存。示例代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
/** 一个固定大小的FIFO替换策略的缓存 */
class FIFOCache<K, V> extends LinkedHashMap<K, V>{
private final int cacheSize;
public FIFOCache(int cacheSize){
this.cacheSize = cacheSize;
}
// 当Entry个数超过cacheSize时,删除最老的Entry
@Override
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return size() > cacheSize;
}
}
WeakHashMap
gc后,如果key和value对象被没别的强引用,就被清了。
TreeMap(& TreeSet) - TODO
参阅
- https://github.com/CarpenterLee/JCFInternals/blob/master/markdown/0-Introduction.md
Collections - 关于Collection的工具类
很多骚方法,比如获取同步容器的Collections.synchronizedXXX方法,由map转set的newSetFromMap()等。
还有很多工具方法,比如binarySearch()、sort()等。
其他 - Guava
Guava提供了不少jdk没有的优质的集合,不过这些集合的使用频率肯定是没有jdk里的集合高的,要不然就该加入jdk了。
Guava的集合只要是为了防止集合嵌套这种不太不明晰的写法,比如:Map<K, Collection<V>>可以用MultiMap取代。
MultiSet
允许一个值出现多次的Set。像是一个不关注顺序的list,同时能方便的统计出每个元素的出现次数。
场景:比如统计一篇文章中每个单词出现的次数。一般使用Map,key为word,value为count。但是写起来比较冗杂,且不方便知道所有单词数(得遍历所有Entry,count相加)。MultiSet拥有count(E),size()等方法,用起来很方便。
MultiMap
用来取代Map<K, Collection<V>>,value支持多值。
但是MultiMap并不是Map<K, Collection<V>>,它的底层还是一个个的key-> value,不过MultiMap允许key重复。只有当使用asMap()方法时,MultiMap才呈现出Map<K, Collection<V>>的视图。比如MultiMap的size()方法返回的并不是所含有的Collection的个数(它底层没有这种Collection),而是所有的key -> value的个数(重复的key -> value算是多个)。
只有使用asMap之后,MultiMap才是
Map<K, Collection<V>>。
BiMap
用于比如nameToId,idToName的场景,key和value需要相互映射。只需要reverse()方法即可。
Table
对表格的抽象。表格需要用行和列来确定一个值。Table就是Row,Colum,Value的三元组。put(R, C, V)往表里放元素,get(R, C)使用某行某列则可以取出确定的一个值。
当调用rowMap()的时候,返回的就是Map<R, Map<C, V>>,每一个row对应的<colum, value>这一map。
Map<R, Map<C, V>>这种map套map,实际上就是一个Table。 仔细想想,一个表也可以使用树状形式画出来。
RangeSet
创建各种开闭区间,merge在一次,方便地判断某数值是否在区间内。结合Guava的Range类使用。
1
2
3
4
5
6
RangeSet<Integer> rangeSet = TreeRangeSet.create();
rangeSet.add(Range.closed(1, 10)); // {[1, 10]}
rangeSet.add(Range.closedOpen(11, 15)); // disconnected range: {[1, 10], [11, 15)}
rangeSet.add(Range.closedOpen(15, 20)); // connected range; {[1, 10], [11, 20)}
rangeSet.add(Range.openClosed(0, 0)); // empty range; {[1, 10], [11, 20)}
rangeSet.remove(Range.open(5, 10)); // splits [1, 10]; {[1, 5], [10, 10], [11, 20)}
RangeMap
1
2
3
4
5
RangeMap<Integer, String> rangeMap = TreeRangeMap.create();
rangeMap.put(Range.closed(1, 10), "foo"); // {[1, 10] => "foo"}
rangeMap.put(Range.open(3, 6), "bar"); // {[1, 3] => "foo", (3, 6) => "bar", [6, 10] => "foo"}
rangeMap.put(Range.open(10, 20), "foo"); // {[1, 3] => "foo", (3, 6) => "bar", [6, 10] => "foo", (10, 20) => "foo"}
rangeMap.remove(Range.closed(5, 11)); // {[1, 3] => "foo", (3, 5) => "bar", (11, 20) => "foo"}
暂时没想起来什么用途。感觉像是划分地皮,A到B的区间属于我,C到D属于你之类的。
参阅
- https://github.com/google/guava/wiki/NewCollectionTypesExplained